

اختصاصی ژاکت – در مقالهای که توسط تیم تحقیقاتی Apple منتشر شده، مدلهای زبان بزرگ هوش مصنوعی که برای پردازش زبان طبیعی، حل مسائل پیچیده و انجام محاسبات ریاضی مورد استفاده قرار میگیرند ظاهراً قادر به درک واقعی مفاهیم ریاضی نیستند. در عوض، آنها تنها الگوهای نمادین را شناسایی میکنند، بدون اینکه از مفهوم انتزاعی آگاه باشند.
این یافتهها نگرانیهای عمیقی را درباره محدودیتهای این مدلها در زمینههایی که نیاز به استدلال انتزاعی و رسمی دارند، مطرح میکند.
برای درک بهتر آنچه که قرار است در ادامه بخوانید یک مثال ساده می زنیم:
شما در مدرسه یاد کرفته اید که 2*2 برابر با عدد 4 است و همینطور 4*3 می شود 12. اینجا معلم به شما مفهوم ضرب را یاد می دهد و به شما این مفهوم را آموزش می دهد که چطور اعداد با اعمال ضرب به یک نتیجه می رسند. درواقع شما یاد می گیرید که ضرب چه کاری انجام می دهد و به همین ترتیب می توانید اعداد بزرگ را هم فارغ از اینکه در مدرسه تمرین کرده باشید یا نه انجام دهید.
اما مدل های زبان اینگونه نیستند و اغلب برای درک مفاهیم با مشکل مواجه می شوند. فرض کنید به یک مدل هوش مصنوعی یاد میدهیم که صرب اعداد را بفهمد. این مدل یاد میگیرد که ۲ * ۳ = 6 و ۴ * ۵ = 20. حالا اگر به آن بگوییم ۱۰۰ * ۲۰۰ چقدر میشود، ممکن است جواب اشتباهی بدهد یا نتواند درست محاسبه کند، چون قبلاً مثالهای مشابهی ندیده است و فقط الگوهایی از جمعهای کوچک را به خاطر سپرده است. درحالیکه اگر این مدل قاعده کلی ضرب را درک کرده بود، میتوانست هر عددی را بدون مشکل ضرب کند، مثل یک انسان که مفهوم ضرب را میفهمد.
مدلهای زبانی بزرگ: الگوشناسی به جای استدلال
یکی از مهمترین کشفیات پژوهشگران Apple این بود که مدلهای زبانی بزرگ مثل GPT، تنها بر اساس الگوهایی که از دادههای آموزشی خود یاد گرفتهاند، مسائل ریاضی را حل میکنند. این مدلها به جای استدلال انتزاعی و درک مفهومی، صرفاً به دنبال تطبیق الگوهای ریاضی در دادههای ورودی هستند. این بدان معناست که اگر تغییری کوچک در مسئله ایجاد شود، مثل تغییر نامها یا عبارات، ممکن است مدل نتایج متفاوتی ارائه دهد. در واقع، حتی تغییر یک نام میتواند نتایج را تا ۱۰٪ تغییر دهد، که نشان میدهد این مدلها از قواعد کلی پیروی نمیکنند و به شدت به الگوهای دیدهشده وابستهاند.
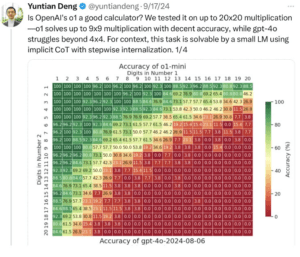
مشکل در تعمیمپذیری و حل مسائل پیچیده
یکی از بزرگترین محدودیتهای مدلهای زبانی بزرگ این است که با افزایش پیچیدگی مسائل، عملکرد آنها به شدت کاهش مییابد. در آزمایشهای متعدد، مشاهده شده که این مدلها در حل مسائل کوچکتر عملکرد نسبتاً خوبی دارند، اما وقتی مسائل پیچیدهتر میشوند یا نیاز به محاسبات بزرگتری دارند، عملکردشان به شدت افت میکند.
مثال:
مدلی که ممکن است بتواند مسائل سادهای مثل 2+22 + 22+2 یا 5×45 \times 45×4 را حل کند، وقتی با ضربهای بزرگتری مانند 324×297324 \times 297324×297 مواجه میشود، دچار خطا میشود. این در حالی است که یک ماشینحساب معمولی همیشه با دقت ۱۰۰٪ این مسائل را حل میکند، اما مدلهای زبانی بزرگ به دلیل ناتوانی در تعمیم مفاهیم، نتایج دقیقی ارائه نمیدهند.
شکنندگی در برابر اطلاعات اضافی
یکی دیگر از مشکلات این مدلها شکنندگی آنها در برابر تغییرات کوچک یا اضافه کردن اطلاعات غیرضروری به یک مسئله است. اضافه کردن حتی کمی اطلاعات نامربوط به یک مسئله، میتواند مدل را دچار اشتباه کند و نتیجهگیری نادرستی ارائه دهد. این نشان میدهد که LLMها درک واقعی از مفاهیم پیچیده ندارند و تنها بر اساس تطبیق الگوهای قبلی پاسخ میدهند.
مثال:
فرض کنید مسئلهای درباره جمع اعداد وجود دارد که یک مدل زبان باید پاسخ دهد. اگر به مسئله اطلاعات اضافی اضافه شود، مدل ممکن است نتواند به درستی پاسخ دهد و دچار سردرگمی شود. این نوع مشکلات نشاندهنده شکنندگی در الگوهای تطبیقی است.
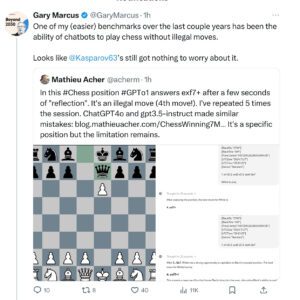
شکست در پیروی از قواعد رسمی
یکی از نتایج مهم این مطالعه نشان میدهد که مدلهای زبانی بزرگ حتی قواعد رسمی را به درستی نمیتوانند رعایت کنند. به عنوان مثال، در بازیهایی مثل شطرنج، این مدلها بارها قوانین بازی را نقض کرده و حرکتهای غیرقانونی انجام دادهاند. این مسئله به طور مستقیم با ناتوانی آنها در استدلال رسمی و انتزاعی مرتبط است.
مثال:
مدلی که برای بازی شطرنج آموزش دیده است، ممکن است حرکتهای غیرقانونی مانند جابهجایی مهرهها به صورت نامعتبر را انجام دهد، چرا که نمیتواند قواعد کلی بازی را به درستی درک کند و به آنها پایبند بماند.
مثالی دیگر:
یکی از مشکلات بزرگ ابزارهای هوش مصنوعی ضعف آنها در پیروی از قواعد و قوانین کتابخانه ها است. به عنوان مثال اگر از یک مدل زبان بخواهید یک قطعه کد سمنتیک برای شما بنویسد و از قواعد کتابخانه ای پیروی کند، در 99% مواقع پاسخ را بر اساس پرامپت شما تولید می کند و قوانین رسمی کتابخانه و ویژگی ها را درک نمی کند.
نتیجهگیری کلی این است که این مدلهای هوش مصنوعی، به تنهایی نمیتوانند عاملهای قابل اعتمادی برای حل مشکلات پیچیده باشند، زیرا توانایی استدلال انتزاعی و منطقی کافی ندارند. نویسنده معتقد است که برای پیشرفت در این حوزه، باید از ترکیب شبکههای عصبی با سیستمهای نمادین (مانند آنچه در جبر یا برنامهنویسی استفاده میشود) استفاده کرد تا بتوان به راهحلهای بهتری دست یافت.
پرداختن به این موضوع از اهمیت زیادی برخوردار است زیرا بسیاری از افرادی که از ابزارهای هوش مصنوعی استفاده می کنند، دانش و تخصص کافی برای درک پاسخ های اشتباه و درست این مدل های زبان را ندارند.
این بزرگ ترین تفاوت میان ادراک انسان با هوش مصنوعی هست، مانند درک مفاهیم ناموجود از هیچ که فقط در حیطه ذهن انسان در دسترس است.
تحریریه ژاکت
مشاهده تیم تحریریه

