

فایل robots.txt مجموعه ای از دستورالعمل ها برای ربات ها است. این پرونده در پرونده های منبع اکثر وب سایت ها موجود است. پرونده های Robots.txt بیشتر برای مدیریت فعالیت ربات های خوب مانند خزنده های وب در نظر گرفته شده است، زیرا ربات های بد احتمالاً از این دستورالعمل ها پیروی نمی کنند. در ادامه بیشتر توضیح می دهیم که فایل robots.txt چیست پس با ما همراه باشید.
ربات، یک برنامه رایانه ای خودکار است که با وب سایت ها و برنامه ها ارتباط برقرار می کند. ربات های خوب و ربات های بد وجود دارند و یکی از انواع ربات های خوب ربات خزنده وب نام دارد. این ربات ها صفحات وب را جست و جو می کنند و محتوا را فهرست می کنند تا بتواند در نتایج موتور جستجو نشان داده شود. یک فایل robots.txt به مدیریت فعالیت های این خزنده های وب کمک می کند تا از این طریق وب سرور میزبان وب سایت یا صفحاتی را که برای بازدید عموم در نظر گرفته نشده اند، اضافه کند.
robots.txt در کجای یک سایت قرار می گیرد؟
ربات ها فقط در یک مکان خاص به دنبال آن پرونده می گردند که آن دایرکتوری اصلی شما است. اگر یک ربات به آدرس www.example.com/robots.txt مراجعه کند و پرونده رباتی را در آنجا پیدا نکند، فرض می کند سایت فاقد یک پرونده است و به شروع به خزیدن در صفحه های شما و شاید کل سایت کند.
برای اطمینان از یافتن فایل robots.txt، همیشه آن را در فهرست اصلی یا دامنه اصلی خود قرار دهید.

چرا به robots.txt نیاز دارید؟
تا اینجا گفتیم فایل robots.txt چیست و در کجای سایت قرار می گیرد. پرونده های Robots.txt دسترسی خزنده را به مناطق خاصی از سایت شما کنترل می کنند. اگر شما به طور تصادفی اجازه ندهید Googlebot به جستجوی کل سایت شما بپردازد، برای سئو وب سایت شما بسیار خطرناک است، اما شرایطی وجود دارد که یک فایل robots.txt می تواند بسیار مفید باشد.
برخی موارد استفاده معمول شامل موارد زیر است:
- جلوگیری از نمایش محتوای تکراری در SERP (توجه داشته باشید که ربات های متا اغلب گزینه بهتری برای این کار هستند)
- خصوصی نگه داشتن کل بخشهای یک وب سایت (به عنوان مثال سایت شخصی )
- جلوگیری از نمایش صفحات نتایج جستجوی داخلی در SERP عمومی
- تعیین محل نقشه سایت (ها)
- جلوگیری از نمایه سازی موتور های جستجو در پرونده های خاص وب سایت شما (تصاویر، PDF و غیره)
- مشخص کردن تأخیر خزیدن به منظور جلوگیری از سربار شدن سرورهای شما هنگام بارگیری همزمان چندین محتوای خزنده ها
اگر در سایت شما هیچ منطقه ای وجود ندارد که بخواهید دسترسی عامل کاربر را به آن کنترل کنید، ممکن است به هیچ وجه به یک پرونده robots.txt نیازی نداشته باشید.
آیا شما یک فایل robots.txt دارید؟
یک فایل robots.txt فقط یک فایل متنی است و درست مثل سایر پرونده های وب سایت روی وب سرور میزبانی می شود. در واقع، می توان فایل robots.txt را برای هر وب سایت مشخصی با تایپ URL کامل صفحه اصلی و سپس افزودن /robots.txt، مانند مشاهده کرد . این پرونده به جایی دیگر در سایت پیوند ندارد، بنابراین کاربران احتمالاً به آن سر نخواهند خورد، اما اکثر ربات های خزنده وب قبل از اینکه بقیه سایت را بخزند ابتدا به دنبال این پرونده می گردند.
در حالی که یک فایل robots.txt دستورالعمل هایی برای ربات ها ارائه می دهد، در واقع نمی تواند دستورالعمل ها را اجرا کند. یک ربات خوب، مانند یک خزنده وب ، سعی می کند قبل از مشاهده سایر صفحات موجود در یک دامنه، ابتدا از پرونده robots.txt بازدید کند و دستورالعمل ها را دنبال می کند. ربات بد یا فایل robots.txt را نادیده می گیرد یا برای یافتن صفحات وب ممنوع پردازش می کند.
ربات خزنده وب خاص ترین دستورالعمل ها را در پرونده robots.txt دنبال می کند. اگر دستورات متناقضی در پرونده وجود داشته باشد، ربات از دستور دقیق تر پیروی می کند.
یک نکته مهم که باید به آن توجه کنید این است که همه زیر دامنه ها به پرونده robots.txt خود نیاز دارند. به عنوان مثال، در حالی که www.example.com پرونده خود را دارد، همه زیر دامنه های example (blog.example.com، community.example.com و غیره) نیز به موارد خاص خود نیاز دارند.
از چه پروتکل هایی در پرونده robots.txt استفاده می شود؟
در شبکه، پروتکل فرمی برای ارائه دستورالعمل ها یا دستورات است. پرونده های Robots.txt از چند پروتکل مختلف استفاده می کنند. پروتکل اصلی Robots Exclusive Protocol نامیده می شود. این روشی است که باید به ربات ها بگویید از کدام صفحات وب و منابع خودداری کنید. دستورالعمل های قالب بندی شده برای این پروتکل در پرونده robots.txt موجود است.
پروتکل دیگری که برای پرونده های robots.txt استفاده می شود پروتکل Sitemaps است. این را می توان یک پروتکل درج ربات در نظر گرفت. نقشه های سایت یک خزنده وب را نشان می دهد که از کدام صفحات می توانند استفاده کنند. این به شما اطمینان می دهد که ربات خزنده هیچ صفحه مهمی را از دست نخواهد داد.
نمونه ای از فایل robots.txt
در اینجا فایل robots.txt برای یک نمونه سایت آمده است:
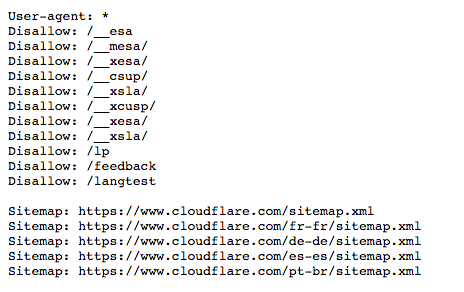
قالب اصلی:
User-agent: [user-agent name] Disallow: [URL string not to be crawled]
این دو خط با هم یک پرونده کامل robots.txt در نظر گرفته می شوند – اگرچه یک پرونده ربات می تواند شامل چندین خط عامل و دستورالعمل کاربر باشد (به عنوان مثال، اجازه نمی دهد، تأخیر خزیدن، و غیره).
در یک فایل robots.txt، هر مجموعه از دستورالعمل های عامل کاربر به عنوان یک مجموعه گسسته ظاهر می شوند، که با یک خط شکاف جدا می شوند:
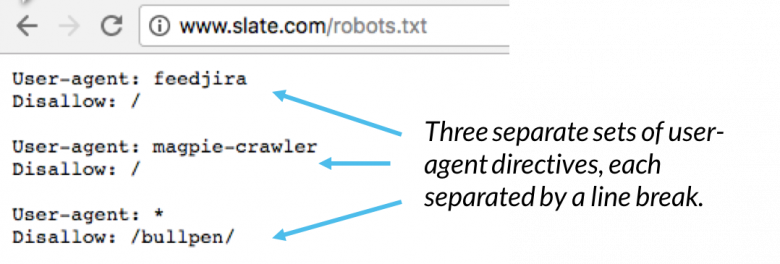
اگر پرونده حاوی محتوای قانونی باشد که برای بیش از یک عامل کاربر اعمال می شود، یک خزنده فقط به خاص ترین گروه دستورالعمل ها توجه می کند (و دستورالعمل ها را دنبال می کند) .
نماینده کاربری (user agent) چیست؟ منظور از ‘User-agent: *’ چیست؟
هر شخص یا برنامه فعال در اینترنت “user agent” یا نام اختصاصی خواهد داشت. برای کاربران انسانی، این شامل اطلاعاتی مانند نوع مرورگر و نسخه سیستم عامل است اما اطلاعات شخصی ندارد. این به وب سایت ها کمک می کند تا محتوای سازگار با سیستم کاربر را نشان دهند. برای ربات ها،user agent (از لحاظ تئوری) به مدیران وب سایت کمک می کند تا بدانند چه نوع ربات هایی در سایت خزنده هستند.
در یک فایل robots.txt، مدیران وب سایت می توانند با نوشتن دستورالعمل های مختلف برای نمایندگان کاربر ربات، دستورالعمل های خاصی را برای ربات های خاص ارائه دهند. به عنوان مثال، اگر یک مدیر بخواهد یک صفحه خاص در نتایج جستجوی گوگل نشان داده شود، اما در جستجوی Bing نشان ندهد، آن ها می توانند شامل دو مجموعه دستور در پرونده robots.txt باشند: یک مجموعه قبل از “User-agent: Bingbot” و یک مجموعه قبل از آن “User-agent: Googlebot”.
در مثال بالا، Cloudflare “User-agent: *” را در پرونده robots.txt قرار داده است. ستاره نشان دهنده user agent “wild card” است و به این معنی است که دستورالعمل ها برای هر ربات و نه هر ربات خاص اعمال می شوند.
user agent کاربری متداول ربات موتور جستجو شامل موارد زیر است:
گوگل:
- Googlebot
- Googlebot-Image (برای تصاویر)
- Googlebot-News (برای اخبار)
- Googlebot-Video (برای فیلم)
بینگ:
- Bingbot
- MSNBot-Media (برای تصاویر و فیلم)
Baidu
- Baiduspider
چگونه دستورات ‘Disallow’ در یک فایل robots.txt کار می کنند؟
حال می دانیم فایل robots.txt چیست باید بدانید که دستور Disallow رایج ترین در پروتکل حذف ربات ها است. این به ربات ها می گوید که به صفحه وب یا مجموعه ای از صفحات وب که بعد از دستور می آیند دسترسی پیدا نکنند. صفحات غیرمجاز لزوماً “پنهان” نیستند – فقط برای یک کاربر متوسط Google یا Bing مفید نیستند، بنابراین برای آن ها نمایش داده نمی شود. در بیشتر مواقع، یک کاربر در وب سایت اگر بداند از کجا می تواند این صفحات را پیدا کند، همچنان می تواند به این صفحات هدایت شود.
از دستور Disallow می توان به روش های مختلفی استفاده کرد:
مسدود کردن یک فایل (به عبارت دیگر، یک صفحه وب خاص)
به عنوان مثال، اگر سایتی بخواهد مانع خزیدن ربات ها در مقاله “ربات چیست؟ ” شود، چنین دستوری به شرح زیر نوشته می شود:
Disallow: /learning/bots/what-is-a-bot/
پس از دستور “disallow”، بخشی از URL صفحه وب که بعد از صفحه اصلی می آید – در این مورد، “www.example.com” – موجود است. با استفاده از این دستور، ربات های خوب به دسترسی نخواهند داشت و صفحه در نتایج موتور جستجو نشان داده نمی شود.
مسدود کردن یک فهرست
بعضی اوقات مسدود کردن چندین صفحه به طور همزمان، به جای فهرست کردن همه آنها به صورت جداگانه، کارایی بیشتری دارد. اگر همه آن ها در یک بخش از وب سایت قرار داشته باشند، یک فایل robots.txt می تواند فهرست راهنمای موجود در آنها را مسدود کند.
مثالی از بالا:
Disallow: /__mesa/
این بدان معنی است که تمام صفحات موجود در فهرست __mesa نباید خزیده شوند.
دسترسی کامل را مجاز کنید
چنین فرمانی به شرح زیر است:
Disallow:
این به ربات ها می گوید که آنها می توانند کل وب سایت را مرور کنند، زیرا هیچ چیز مجاز نیست.
پنهان کردن کل وب سایت از ربات ها
Disallow: /
“/” در اینجا نشان دهنده root در سلسله مراتب وب سایت یا صفحه ای است که سایر صفحات از آن منشعب می شوند، بنابراین شامل صفحه اصلی و تمام صفحات پیوند یافته از آن است. با استفاده از این دستور، ربات های موتور جستجو به هیچ وجه نمی توانند وب سایت را جستجو کنند.
به عبارت دیگر، تنها یک علامت اسلش می تواند کل وب سایت را از اینترنت قابل جستجو حذف کند!
چه دستورات دیگری بخشی از پروتکل حذف Robots هستند؟
Allow: همانطور که انتظار می رود، دستور “allow” به ربات ها می گوید که مجاز به دسترسی به یک صفحه وب یا فهرست خاص هستند. این دستور امکان دسترسی به ربات ها به یک صفحه وب خاص را فراهم می کند، در حالی که بقیه صفحات وب موجود در پرونده را مجاز نمی داند. همه موتور های جستجو این دستور را تشخیص نمی دهند.
Crawl-delay: منظور از دستور تاخیر خزنده این است که ربات های عنکبوتی موتور جستجو از اضافه بار گرفتن سرور جلوگیری کنند. به مدیران این امکان را می دهد که میلی ثانیه، مدت زمان انتظار ربات در بین هر درخواست را مشخص کنند. در اینجا مثالی از دستور Crawl-delay برای انتظار 8 میلی ثانیه آورده شده است:
Crawl-delay: 8
گوگل این دستور را تشخیص نمی دهد، اگرچه موتور های جستجوی دیگر این کار را انجام می دهند. برای Google، سرپرستان می توانند فرکانس خزش را برای وب سایت خود در سرچ کنسول تغییر دهند.
پروتکل نقشه سایت در فایل robots.txt چیست؟
پروتکل Sitemaps به ربات ها کمک می کند تا بدانند چه چیزی را باید در خزیدن وب سایت خود قرار دهند.
Sitemap یک فایل XML است که به صورت زیر است:
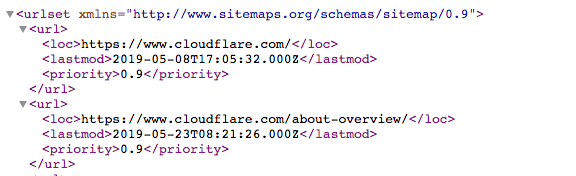
این یک لیست قابل خواندن توسط ماشین از تمام صفحات یک وب سایت است. از طریق پروتکل Sitemaps، پیوند به این نقشه های سایت می تواند در پرونده robots.txt موجود باشد. قالب به صورت زیر است: “نقشه سایت:” و به دنبال آن آدرس وب فایل XML وجود دارد. چندین نمونه را می توانید در فایل Cloudflare robots.txt در بالا مشاهده کنید.
در حالی که پروتکل Sitemaps به شما اطمینان می دهد که ربات های عنکبوتی وب در هنگام جستجوی وب سایت چیزی را از دست ندهند، ربات ها همچنان روند خزیدن معمول خود را دنبال می کنند. نقشه های سایت ربات های خزنده را مجبور نمی کند صفحات وب را به ترتیب متفاوت اولویت بندی کنند.
ارتباط robots.txt با مدیریت ربات چگونه است؟
مدیریت ربات ها برای پایدار نگه داشتن وب سایت یا برنامه ضروری است، زیرا حتی فعالیت خوب ربات می تواند از یک سرور مبدا سو overt استفاده کند، باعث کند شدن یا از بین بردن خاصیت وب شود. یک فایل robots.txt به خوبی ساخته شده یک وب سایت را برای سئو بهینه سازی کرده و فعالیت ربات را تحت کنترل دارد.
با این حال، یک فایل robots.txt کار چندانی در مدیریت ترافیک ربات مخرب نخواهد داشت. یک راه حل مدیریت ربات می تواند به فعالیت ربات مخرب کمک کند بدون اینکه روی ربات های اساسی مانند خزنده های وب تأثیر بگذارد .
امیدواریم با خواندن این مقاله دریافته باشید که فایل robots.txt چیست و چه کاربردی در سایت ها دارد.
ژاکت را دنبال کنید
ژاکت در اینستاگرام
ژاکت در فیسبوک
ژاکت در لینکدین
ژاکت در توییتر
فعلی
فایل robots.txt چیست و چه کاربردی در سایت ها دارد؟
تحریریه ژاکت
مشاهده تیم تحریریه

 مطالب مشابه
مطالب مشابه


![درون ریزی محصولات ووکامرس [آپدیت 2025]](https://blog.zhaket.com/wp-content/uploads/2021/10/import-and-export-of-woocommerce-products-training-300x300.jpg)

![لیست سیاه گوگل چیست؟ [ آموزش خروج از لیست سیاه گوگل]](https://blog.zhaket.com/wp-content/uploads/2025/05/removal-from-google-blacklis-300x300.jpg)


